基于 Dify 的 AI 多维单证自动化处理系统

可拓展方向
- 国际货代:自动扫描并录入海运提单,减少提单号(B/L No.)输入错误。
- 企业财务中心:自动化应付账款(AP)处理,将 PDF 发票直接转化为报销凭证。
- 跨境电商:快速审核装箱单与采购单,实时比对货物重量与体积差异。
项目背景
项目背景 在国际贸易与财务审计场景中,单证处理长期面临以下挑战:
- 人工录入低效:每日处理数百份发票(Invoice)、装箱单(PL)和提单(BL),耗费大量人力。
- 数据质量参差不齐:原始文档常包含错别字(如将 Gross 写成
Gr0ss)、非标排版或中英双语混排,传统 OCR 难以精准结构化。 - 系统孤岛:OCR 提取后的原始文本与企业最终需要的业务报表之间存在“断层”,缺乏逻辑校验与自动汇总能力。
整体架构
graph TD
subgraph Input
A[飞书 Webhook 实时监控] -->|推送文件/消息| B[批量手动上传接口]
end
subgraph 识别层 OCR & Parse
C[批量提取节点] -->|PDF/Word/Excel/图片| D[原始长字符串]
end
subgraph 路由层
E[Jinja2 上下文锚点对齐] --> F[LLM 单证类型分类]
F --> G{发票/合同/提单/其他}
end
subgraph 执行层
H[迭代节点 - 并行运行] --> I[分支1: 发票字段提取]
H --> J[分支2: 合同字段提取]
H --> K[分支3: 提单字段提取]
I & J & K --> L[聚合各单证结构化数据]
end
subgraph 数据清洗层
M[Python 节点] --> N[正则清洗 Markdown 标签]
N --> O[String → Object 类型转换]
end
subgraph 输出层
P[聚合数据渲染] --> Q[飞书消息卡片推送]
end
B --> C
D --> E
F --> G
G --> H
L --> M
O --> P
classDef layer fill:#f0f0f0,stroke:#333,stroke-width:1px;
class Input,OCR,Class,Exec,Clean,Output layer;
系统通过 Dify 工作流编排,实现了从“非结构化文本”到“结构化决策”的闭环。
- 输入层 (Input):支持飞书 Webhook 实时监控转发或批量手动上传。
- 识别层 (OCR & Parse):利用
批量提取节点将各类文档(PDF/Word/Excel/图片)转为原始长字符串。 - 路由层 (Classification):通过 Jinja2 模板进行“上下文锚点对齐”,引导 LLM 准确判断单证类型(发票、合同、提单等)。
- 执行层 (Parallel Extraction):开启迭代节点的 “并行运行” 模式,多分支同步提取各单证核心字段。
- 数据清洗层 (Python Bridge):利用 Python 节点进行正则清洗,剥离 Markdown 标签并完成
String到Object的类型转换。 - 输出层 (Feishu Card):将聚合后的数据渲染为飞书消息卡片进行推送。
功能展示:
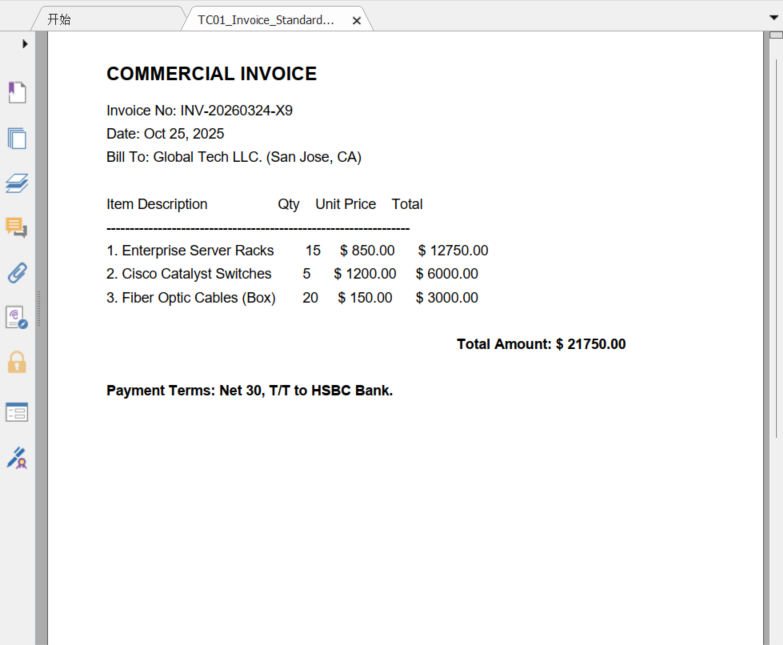
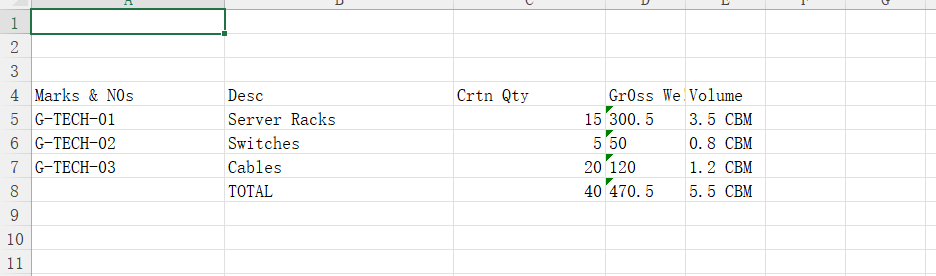
1.准备3个文件测试
TC01_Invoice_Standard.pdf(发票),TC02_PackingList_Messy.xlsx(装箱单),TC03_BillOfLading_Bilingual.docx(提单)

2.执行工作流
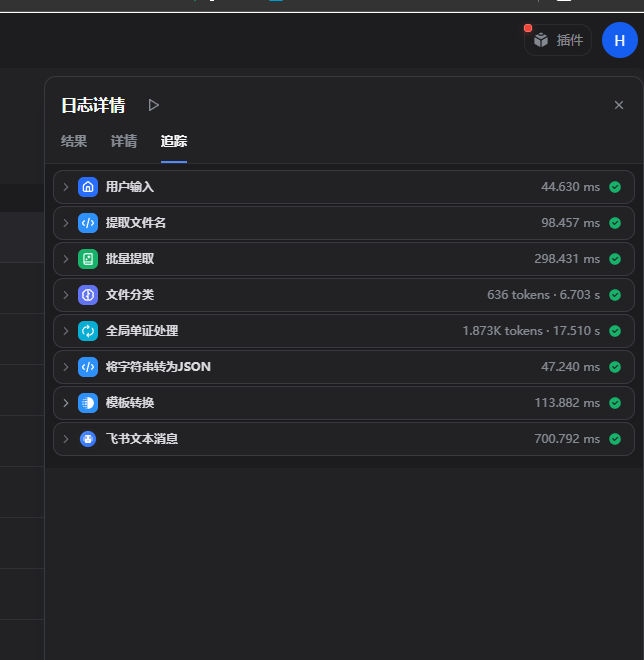
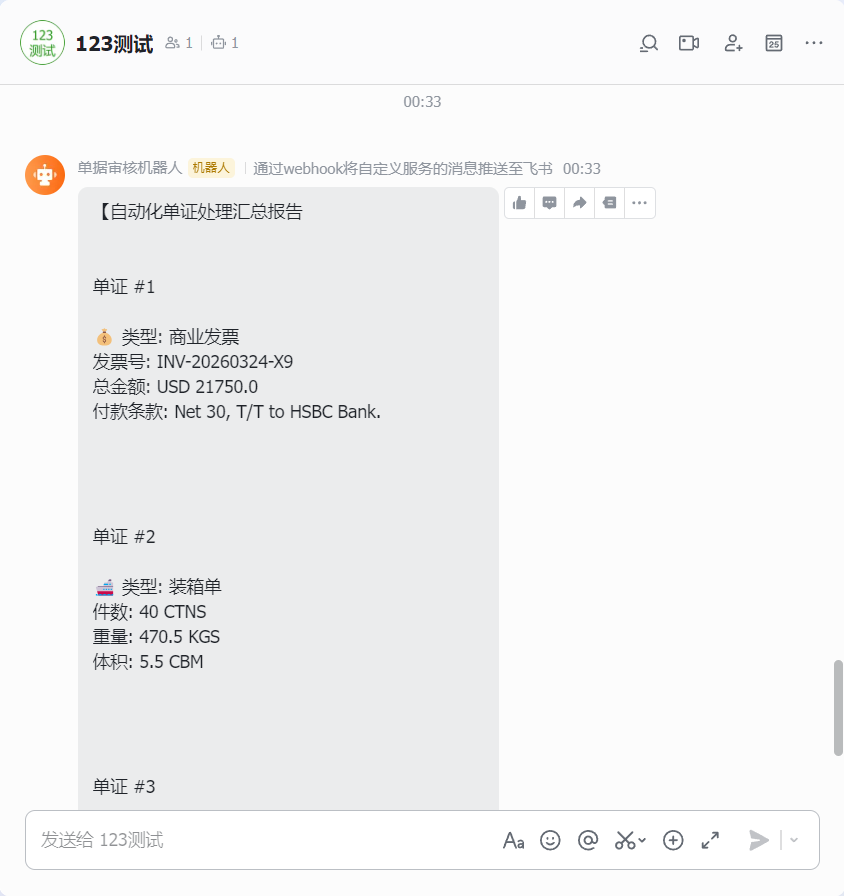
3.查看结果
消息提取后,可以对接任意平台,不论是你飞书,还是企业微信,还是钉钉或者是ERP系统都是可以的
核心亮点
- 极强的容错性:Prompt 注入了“财务审计逻辑”,能自动识别并修正
Gr0ss We!ght等故意构造的干扰项。 - 并行加速:支持多文件同时处理,显著降低大规模单据处理的等待总时长。
- 数据一致性保障:在 Python 节点中增加了
if not item: continue过滤逻辑,确保最终报告中不会出现null导致的渲染崩溃。 - 中英双语兼容:针对
TC03等提单文件,系统能同时解析中英文地址与物权主体。
主要能力
- 多维度分类:支持发票、装箱单、提单、采购单、合同、保单、报关单等 7+ 种类型识别。
- 财务勾稽校验:自动验证发票中的“单价 × 数量 = 总额”逻辑。
- 物流属性提取:精准抓取毛重(GW)、体积(CBM)及件数(QTY)等核心物理指标。
- 异常拦截:通过
ELSE分支识别非单证类“噪音”文件,防止脏数据进入数据库。 - 结构化汇总:将所有迭代结果聚合为单一的 JSON 数组,方便对接下游 ERP 系统。