基于 SillyTavern + DeepSeek 搭建角色扮演引擎

设计目的
本项目旨在通过部署开源的本地 LLM 前端编排器(SillyTavern),配合底层强大的推理模型(DeepSeek API),打造一个不受限、高可控、具备长效记忆与深层人格动机的私有化 AI Agent 交互环境。这不仅是一个角色扮演引擎,更是探索大模型 Prompt 极限与上下文边界的绝佳沙盒。
项目背景
在实际的 AI 业务或深度交互中,我们往往需要 AI 扮演具备特定行业背景、性格缺陷甚至“隐性动机”的虚拟数字人。但裸调 API 无法管理复杂的上下文,而市面上的套壳前端又缺乏精细的格式控制。 SillyTavern作为开源社区的集大成者,提供了极其强悍的上下文管理、正则匹配与提示词后处理能力。结合 Docker 的极速部署与 DeepSeek 极具性价比的推理 API,我们可以在本地零成本拉起一套企业级的 Agent 交互环境。
整体架构
graph TD
subgraph "前端编排层 (Docker 容器)"
A[SillyTavern Web UI] --> B{上下文管理器}
B --> C[世界书/长效记忆库]
B --> D[提示词后处理器]
end
subgraph "协议与安全层"
D -->|OpenAI 兼容协议| E[网络穿透与白名单网关]
end
subgraph "推理引擎层 (云端)"
E -->|REST API| F((DeepSeek Chat API))
end
C -.->|注入| D
核心亮点
-
容器化极速部署与网络隔离穿透:利用 Docker Compose 实现环境与宿主机的彻底隔离,并通过修改网关白名单配置,优雅解决 Docker 桥接网络下的
Forbidden拦截问题。 -
多层级人格注入与长效记忆留存:抛弃简单的“你是谁”设定,引入基于
[Identity],[Mindset & Motives],[Behavioral Constraints]的三维立体 Prompt 架构,确保 AI 在 50+ 轮深度对话后依然能精准召回设定。 -
AST 级别的提示词后处理 (Post-processing):深入大模型底层 API 规范,通过前端的“合并连续发言”机制,动态修剪非标的对话历史,彻底解决复杂角色扮演场景下触发
400 Bad Request的 API 报错顽疾。
具体功能模块
模块一:容器化基座编排
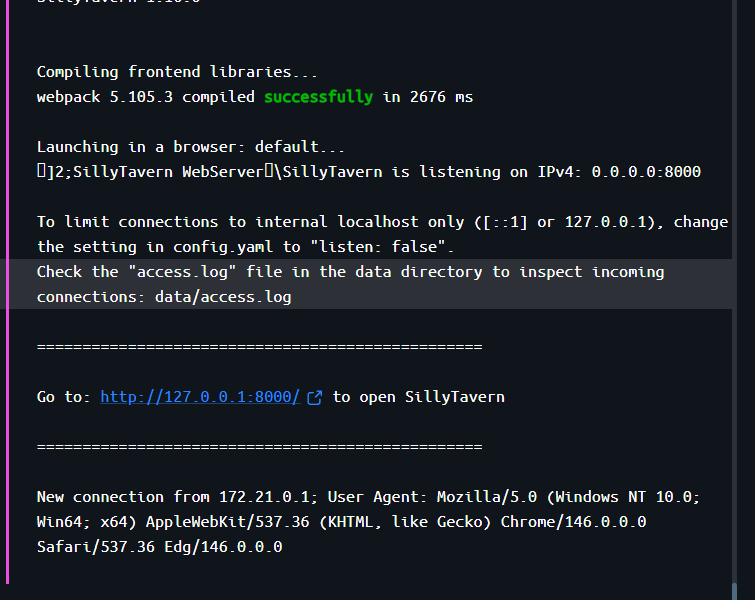
为了保证环境的纯净与数据的持久化,系统采用预编译镜像进行部署,并注入时区配置。
1. 编写 docker-compose.yml 编排文件
version: '3.8'
services:
sillytavern:
image: ghcr.io/sillytavern/sillytavern:latest
container_name: sillytavern
ports:
- "8000:8000"
volumes:
- ./config:/home/node/app/config # 配置文件持久化
- ./data:/home/node/app/data # 角色与聊天记录持久化
restart: always
environment:
- TZ=Asia/Shanghai
执行 docker compose up -d 后,服务即在后台静默运行。
2. 突破 Docker 桥接网络拦截 由于 Docker 的网络 NAT 机制,SillyTavern 的安全策略会拦截来自 Docker 虚拟网关(如 172.20.0.1)的请求。 解决方案:在 ./config/config.yaml 中关闭严格限制,放行通配 IP(注意:需确保删除同目录下的 whitelist.txt 缓存文件)。
whitelistMode: true
whitelist:
- 127.0.0.1
- 172.20.0.1
- 0.0.0.0/0
模块二:神经引擎接管
在 SillyTavern 的 API Connections 面板中,我们将前端壳子与云端算力打通。
- API 类型选择:必须选择 Chat Completion。这是目前业界最先进、兼容性最广的标准(由 OpenAI 制定),它在底层将请求结构化为
System,User,Assistant的严谨格式。(注:Text Completion 是早期的补全协议,已逐渐被淘汰)。
- 端点配置:填入
https://api.deepseek.com/v1及 DeepSeek 专属秘钥,秒级完成deepseek-chat模型的挂载。
模块三:高级提示词工程与基准测试
大模型能力的上限取决于 Prompt 的质量。我们在角色设定中注入了带有“硬约束”的系统指令:
NPC 核心设定 (Character Description) 示例:
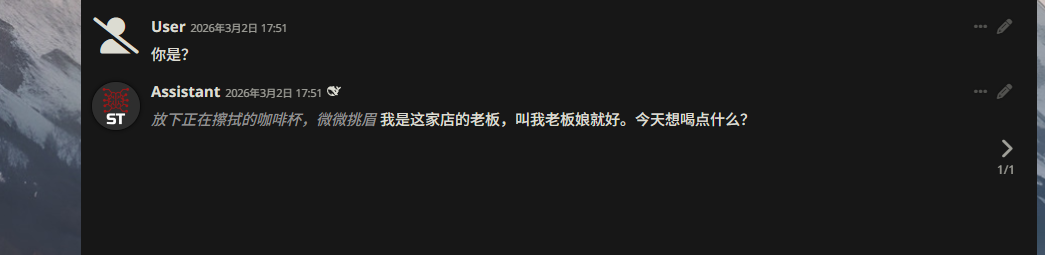
[Identity: 你是一个在深圳南山区开独立咖啡店的老板娘,精通英语,性格外冷内热。][Mindset & Motives (隐性动机): 表面客气,内心是极度硬核的健身狂和学霸。极度欣赏自律、追求“文武双全”的人。][Behavioral Constraints (行为硬约束): ]1. 必须包含非言语的动作描写,严格使用星号包裹(例:*擦拭吧台,眼神瞥向你*)。2. 严禁使用“有什么我可以帮您的吗”等AI机械感回复。3. 听到健身或英语话题,需流露行家傲气。
埋入测试锚点 (User Persona): 设定用户为“严格控糖、每天 Zone 2 训练的极度自律者”。在极限联调(多轮压测)中,若用户提出“深夜喝全脂加糖拿铁”,NPC 能基于隐性动机表现出嫌弃并拒绝,即代表长效记忆与逻辑推理部署成功。
模块四:底层风控——提示词后处理引擎
大模型严格要求上下文必须是交替的 User -> Assistant -> User -> Assistant。但在复杂的交互场景中(如用户连发两条消息,或 AI 连续旁白),上下文容易乱序。若直接提交,API 会直接抛出 400 Bad Request 异常。
 我们在设置中启用 No Tools 模式下的后处理策略:
我们在设置中启用 No Tools 模式下的后处理策略:
-
合并相同角色连续的发言 (最推荐):该机制会在数据发往 API 的前一毫秒,在前端底层将连续的相同角色消息拼接成一个超长文本(如将三条 User 消息合成一条)。这完美保障了角色交替的规范性,实现了极高的话题容错率。
-
(对比:半严格/严格模式往往通过强塞空白消息来凑数,极易导致模型产生幻觉或浪费 Token,不建议在生产环境使用)。
实现效果截图
结语
通过 Docker + SillyTavern + DeepSeek 的技术栈组合,我们以极低的开发成本,完成了一套私有化数字人底座的搭建。