基于Open-LLM-VTuber搭建2D虚拟数字人

可拓展方向
- 自动化全天候 AI 主播:接入 Bilibili/Twitch 弹幕 API 处理互动。
- 本地 AI 助理/口语陪练:离线运行,麦克风输入直连。
- 线下交互看板:用于导览和业务问答。
- 桌面虚拟角色:配合透明化窗口处理,提供系统辅助或闲聊功能。
前提
在开始克隆项目之前,请确保你的电脑上已经安装了以下三个核心软件:
- Git:用于拉取项目源码。
- Docker Desktop。
- Ollama:本地大模型运行器(前往官网下载安装)。
- 2d模型:新着商品 - 通販・ダウンロードの同人販売、購入 - BOOTH
- LLM:qwen2.5大模型
此文章使用
魔女的模型,其他模型也可以
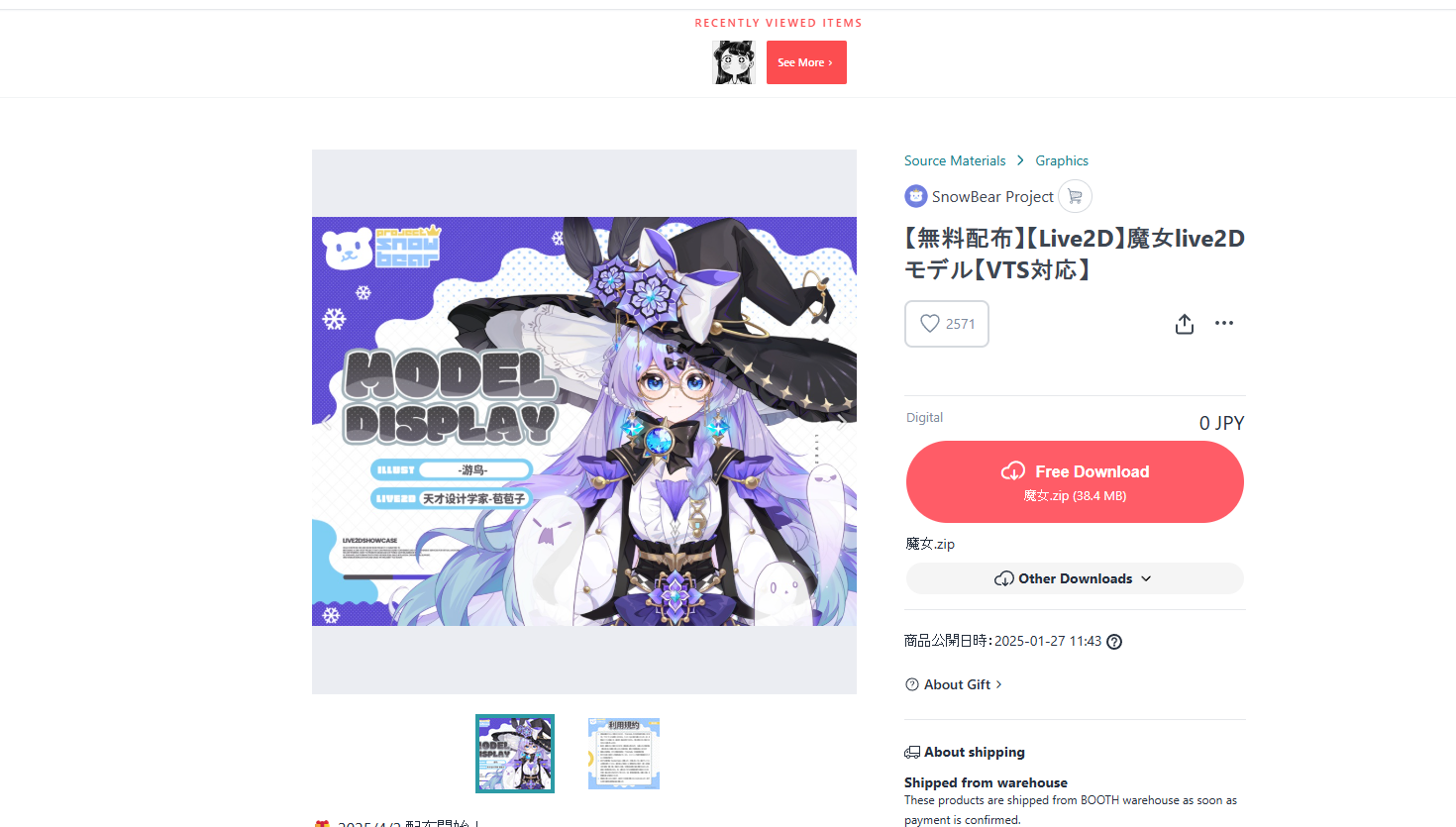
| 文件名 | 角色 / 功能 | 在项目中的作用 |
|---|---|---|
魔女.model3.json | 主配置文件(入口) | 最核心文件。脚手架通过读取它来加载模型、动作和物理。 |
魔女.moc3 | 模型二进制数据 | 存储了角色的网格、顶点等几何数据。 |
魔女.physics3.json | 物理计算 | 让头发、裙摆、欧派能随动作产生自然的摆动。 |
*.exp3.json (多个) | 表情配置文件 | 对应你想要实现的“害羞”、“生气”等情绪。 |
Scene1.motion3.json | 动作序列 | 定义了一个基础的动画(如待机或挥手)。 |
魔女.vtube.json | VTS 兼容配置 | 这是 VTube Studio 的配置文件,AIRI 会参考其中的参数映射。 |
设计目的
提供 Windows 下 Open-LLM-VTuber 本地 Docker 部署的跑通方案。官方文档对容器网络通信和文件解析逻辑说明不足,容易卡在 ERR_EMPTY_RESPONSE、Connection refused 和 string indices must be integers 等问题。本文档重构了部署流程,提供稳定运行路径。
项目背景
Open-LLM-VTuber 是开源的 AI VTuber 驱动框架,支持多模态交互。在 Windows + Docker 部署 v1.2.1 版本时,存在几个明确的技术阻碍:
- 容器网络隔离:容器内部不能直接用
localhost访问宿主机的 Ollama 接口。 - JSON 解析逻辑缺陷:v1.2.1 后端解析自定义 Live2D 模型的
model_dict.json时,若缺失动作节点或嵌套结构异常,会直接抛出异常并退出进程。 - 大文件下载中断:首次启动需下载约 1GB 的 ASR 模型,网络中断会导致缓存损坏。
以下是绕过上述底层逻辑的具体步骤。
整体架构
采用前后端分离与容器化隔离架构。本地部署时,为调用宿主机 GPU 算力,Ollama 需运行在容器外部。
-
前端 WebUI:浏览器访问
127.0.0.1:12393,通过 HTTP/WebSocket 与容器通信。 -
后端容器:
- LLM 网关:处理上下文,经由
host.docker.internal访问 Windows 宿主机 Ollama API。 - Live2D 引擎:解析
.model3.json驱动模型。 - ASR / TTS:内置 Sherpa-Onnx 与 Edge-TTS。
- LLM 网关:处理上下文,经由
-
宿主机侧:独立运行 Ollama 提供
qwen2.5等模型推理服务。
核心要点
- 网络打通:配置环境变量
OLLAMA_HOST=0.0.0.0并使用host.docker.internal实现容器到宿主机的通信。 - 模型加载方案:覆盖官方默认的
mao_pro模型目录,删掉自定义model_dict.json,规避后端的格式解析逻辑。 - 解耦部署:模型推理、环境依赖、业务代码物理分离,方便后续替换 LLM 或 Live2D 资源。
具体功能模块与实施步骤
1. 拉取项目源码
在全英文路径下打开 PowerShell,执行:
git clone https://github.com/Open-LLM-VTuber/Open-LLM-VTuber.git
cd Open-LLM-VTuber
2. 配置 conf.yaml
进入 conf 目录,复制 conf.default.yaml 并重命名为 conf.yaml。修改以下三处配置:
修改前端访问权限 将 host 改为 0.0.0.0。默认的 localhost 会导致 Docker 只监听容器内部网卡,外部浏览器访问会报 ERR_EMPTY_RESPONSE。
system_config:
conf_version: 'v1.2.1'
host: '0.0.0.0'
port: 12393
绑定默认模型 将 live2d_model_name 指向官方默认的 mao_pro。
character_config:
conf_name: 'witch'
conf_uid: 'witch_001'
live2d_model_name: 'mao_pro'
配置 LLM 网络穿透 将 base_url 改为 http://host.docker.internal:11434/v1。不要写 localhost,否则容器无法访问宿主机的 Ollama 接口。
ollama_llm:
base_url: 'http://host.docker.internal:11434/v1'
model: 'qwen2.5:latest'
temperature: 1.0
keep_alive: -1
unload_at_exit: True
3. 替换 Live2D 模型
v1.2.1 版本的后端在解析自定义 model_dict.json 时容易出问题。如果模型文件缺失 Motions 或 Expressions 节点,或者 JSON 嵌套层级不对,进程会直接报 string indices must be integers 异常并退出。
绕过这个解析逻辑的方案是直接覆盖官方模型:
- 进入
models/目录,新建或清空mao_pro文件夹。 - 将你的 Live2D 模型文件(含
.moc3和贴图目录等)全部拷入mao_pro。 - 将主 JSON 文件重命名为
mao_pro.model3.json。 - 删掉
conf/目录下的model_dict.json文件。系统会回退去加载我们覆盖后的官方默认模型目录。
4. 启动容器与依赖下载
回到项目根目录,执行:
docker-compose down
docker-compose up -d
docker-compose logs -f
首次启动会触发 Sherpa-Onnx ASR 模型的下载,体积约 1GB。下载期间保持网络稳定,不要中断进程。等待日志输出 Extraction completed.。中途打断会导致文件损坏,后续启动会抛出解压异常。
5. 运行验证
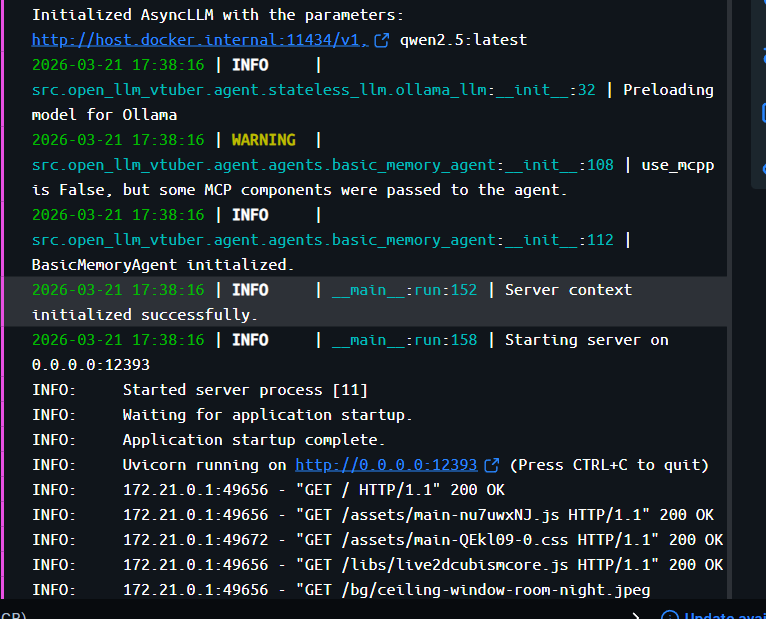
ASR 模型解压完成后,正常加载的日志顺序如下:
Initializing Live2D: mao_proModel Information Loaded.Initialized AsyncLLM with the parameters: http://host.docker.internal:11434/v1Uvicorn running on http://0.0.0.0:12393
确认服务挂载到 12393 端口后,通过浏览器访问 http://127.0.0.1:12393 即可。
6.(可选)可以替换为云端API
打开 conf/conf.yaml,找到 llm_config 区域,以DeepSeek为例子:
1. 切换 LLM 类型
将 llm_type 的值从 ollama_llm 改为 openai_compatible_llm:
llm_config:
llm_type: 'openai_compatible_llm'
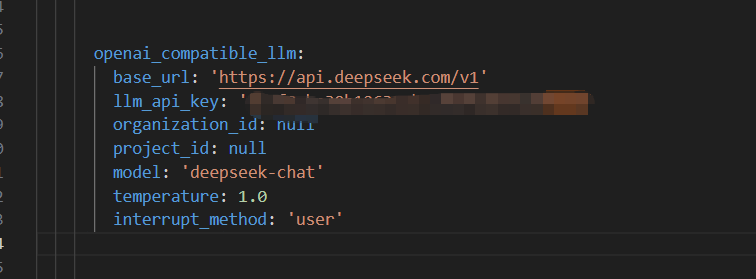
2. 配置 DeepSeek 参数
找到 openai_compatible_llm 模块,填入以下官方参数:
实现效果截图
输入http://127.0.0.1:12393 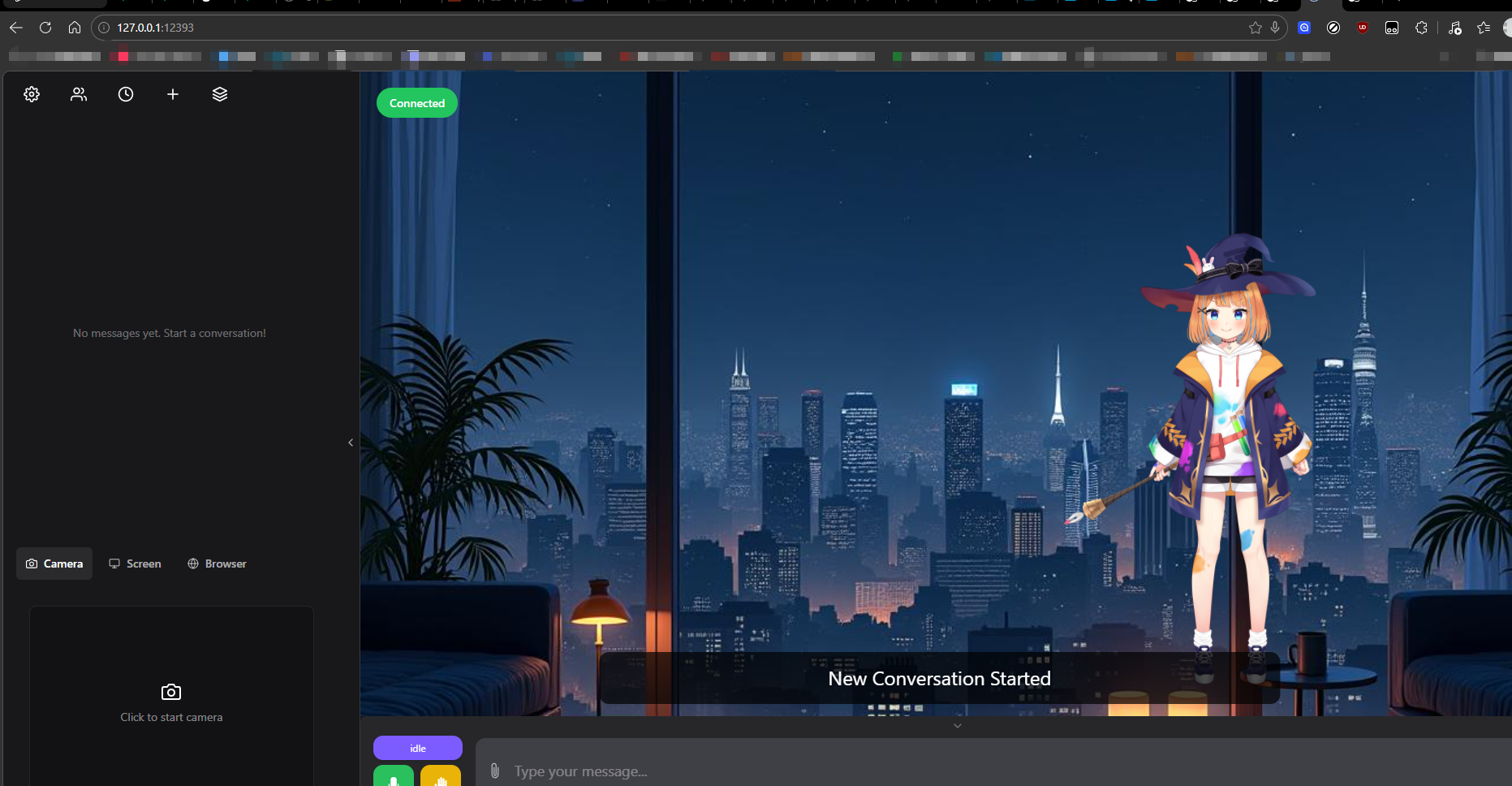
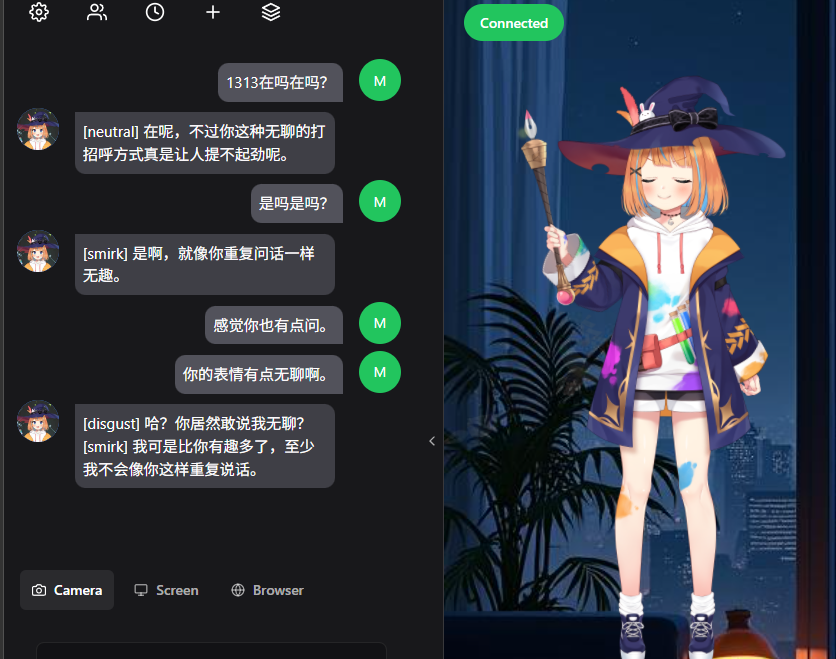
结语
行了,这套逻辑基本上把 Windows 下 Docker 部署的坑全踩平了。 虽然 v1.2.1 的解析器挺脆,网络桥接也挺绕,但只要按这个路径避开那几个硬编码的死穴,整套架构跑起来其实挺稳的。既然环境已经稳了,剩下的就是调优模型和人格,直接开玩就行。